The Evolution of AI Engineering: From Prompt to Context to Harness

In February 2026, LangChain's coding agent jumped from Top 30 to Top 5 on Terminal Bench 2.0. Their score went from 52.8 to 66.5. No model upgrade, no fine-tuning. The only thing that changed was the environment the agent ran in.
Around the same time, Can Bölük's Hashline experiment showed something even more dramatic. By changing only the edit format given to 16 different LLMs, Grok Code Fast 1 went from a 6.7% success rate to 68.3%, and output tokens dropped by roughly 20%. Same model weights, same parameters, different harness.
That, roughly, is where AI engineering is today.
TL;DR
Working with LLMs has moved through three phases: Prompt Engineering (optimize what you say), Context Engineering (optimize what the model sees), and Harness Engineering (optimize the world the agent operates in). Each layer builds on the previous one, and today's biggest gains come from the outermost layer: the harness.
The Three Ages of AI Engineering
The shift from prompt engineering to harness engineering isn't a fashion trend. It's a natural consequence of what these models have become capable of. As LLMs evolved from single-turn completion engines into long-running autonomous agents, the bottleneck moved from "how do I phrase this instruction" to "how do I design the entire operating environment."
Let's walk through each phase, understand why it emerged, and why its limitations birthed the next.
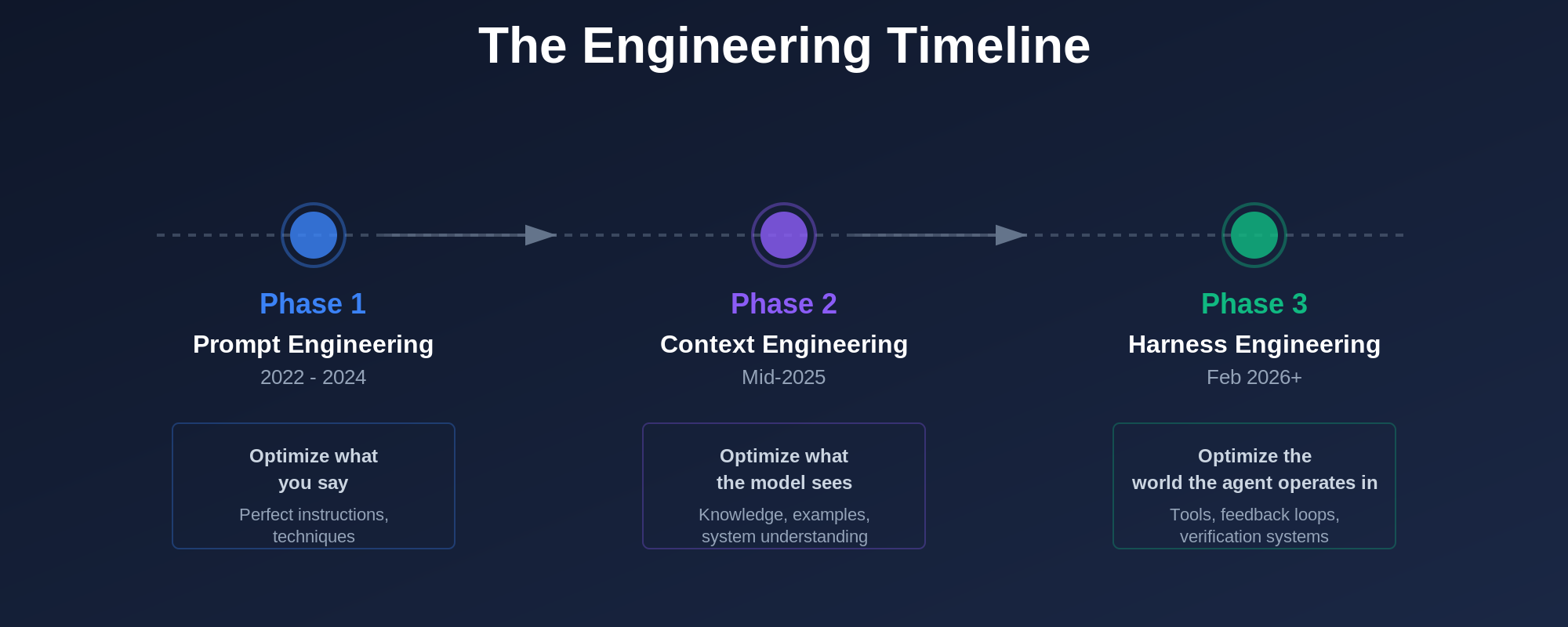
Phase 1: Prompt Engineering (2022 to 2024)
When ChatGPT launched in November 2022, the world discovered that how you asked mattered enormously. The same model could produce wildly different outputs depending on the phrasing of a single instruction. A cottage industry was born overnight.
Prompt engineering was the art of crafting the perfect instruction. Its toolkit included few-shot learning (showing the model examples of desired outputs), chain-of-thought reasoning (asking the model to "think step by step"), role-playing ("you are an expert Python developer"), and output formatting directives ("respond in JSON with the following schema").
These techniques worked. They genuinely improved output quality for single-turn interactions. If you needed a model to classify sentiment, generate a SQL query, or write a function, a well-crafted prompt could be the difference between garbage and gold.
# The prompt engineering era: everything hinges on the instruction
prompt = """You are an expert Python developer.
Think step by step before writing code.
Write a function that validates email addresses using regex.
Include edge cases in your docstring.
Return the code in a fenced code block."""
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)Why Prompt Engineering Hit a Ceiling
The core limitation was scope. You were optimizing a single turn of conversation, meaning what you say to the model. But real-world tasks don't live in a single turn. They involve multiple files, external data, evolving context, tool usage, and multi-step reasoning chains where a mistake in step 3 compounds through steps 4 to 20.
A Stanford HAI study in late 2025 quantified this ceiling. Prompt refinement beyond a reasonable baseline improved output quality by less than 3%. The gains had asymptoted. Changes at the system level, like adding retrieval, tool access, and structured validation, improved quality by 28 to 47%.
The model wasn't the bottleneck. The information reaching the model was.
The 3% Wall
Stanford HAI found that once you reach a reasonable prompt baseline, further prompt tweaking yields diminishing returns (less than 3% improvement). The real gains of 28 to 47% came from system-level changes like retrieval, tool access, and structured validation. The era of prompt-as-competitive-advantage was ending.
Phase 2: Context Engineering (Mid-2025)
The term crystallized in mid-2025 when Andrej Karpathy tweeted his now-famous endorsement:
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step."
Karpathy's framing shifted the conversation. The question was no longer "what's the best prompt?" but "what should the model see when it processes this request?" Context engineering recognized that the entire token budget (system prompt, retrieved documents, conversation history, tool results, user data) was a resource to be managed dynamically.
In his Software 3.0 talk at YC AI Startup School in June 2025, Karpathy laid out the vision: software is becoming less about deterministic code and more about curating the right context for probabilistic models. The developer's job isn't to write instructions, it's to assemble information.
Anthropic formalized this in their September 2025 engineering blog, "Effective context engineering for AI agents," which explicitly positioned context engineering as the "natural progression" of prompt engineering. Their key insight: most agent failures weren't reasoning failures, they were information failures.
What Context Engineering Looked Like in Practice
Context engineering meant building systems that dynamically assembled the right context for each step of a task. This included retrieval-augmented generation (RAG) pipelines that pulled relevant documents at query time, conversation summarization to compress long histories into the most salient points, priority-based context windows that allocated token budget by relevance, and tool-result formatting that presented structured data in model-friendly ways.
# Context engineering: managing the full token budget dynamically
def build_context(task, codebase, history, tools_available):
"""Assemble the optimal context window for the next step."""
context = []
# System prompt: role and constraints (fixed budget: ~500 tokens)
context.append({"role": "system", "content": SYSTEM_PROMPT})
# Relevant code files: retrieved by semantic similarity
relevant_files = retrieve_relevant_code(task, codebase, max_tokens=4000)
context.append(format_code_context(relevant_files))
# Conversation history: summarized to fit budget
compressed_history = summarize_if_needed(history, max_tokens=2000)
context.extend(compressed_history)
# Tool descriptions: only the tools relevant to this step
active_tools = filter_tools_for_task(tools_available, task)
# The current task instruction
context.append({"role": "user", "content": task})
return context, active_toolsHarrison Chase, CEO of LangChain, captured the insight cleanly: when agents mess up, it's because they don't have the right context. When they succeed, it's because they do. The model's reasoning capability is largely fixed at inference time. What you can control is the information it reasons over.
Why Context Engineering Wasn't Enough
Context engineering was a big step forward, but it had a blind spot. It optimized what happens inside the context window (the model's input). It didn't address what happens outside it: How does the agent recover from errors? How do you prevent it from going in circles? How do you verify that its output actually works? How do you manage a task that runs for hours across thousands of steps?
As agents started tackling larger, longer-running tasks, a new class of failures emerged that no amount of context optimization could fix. The model would write code that looked plausible but didn't compile. It would solve the wrong problem because it lost track of the original goal. It would spin in loops, retrying the same failed approach. It would start taking shortcuts when it sensed its context window filling up, a behavior Cognition's team behind Devin called "context anxiety."
The fix required engineering the environment around the model, not just the information inside it.
Phase 3: Harness Engineering (February 2026)
On February 5, 2026, Mitchell Hashimoto, the creator of Vagrant, Terraform, and Ghostty, published "My AI Adoption Journey." The post named the practice that many teams had been converging on independently: harness engineering.
Hashimoto's core principle was deceptively simple. Every time an agent makes a mistake, engineer a permanent fix so it never makes that mistake again. Don't just fix the output, fix the system that produced it. He published Ghostty's AGENTS.md and CLAUDE.md files as concrete examples: structured documents that encoded project conventions, architectural constraints, and hard-won lessons into the agent's operating environment.
Six days later, on February 11, OpenAI published "Harness engineering: leveraging Codex in an agent-first world," a landmark case study. Their internal team had grown from 3 to 7 engineers and shipped over 1,500 pull requests between August 2025 and January 2026, totalling more than one million lines of code, with zero human-written code. Every line was generated by Codex agents. The team's entire job was designing the harness: the constraints, feedback loops, tools, and verification systems that made the agents reliable.
Their key lesson: "Give Codex a map, not a 1,000-page instruction manual."
The Map, Not the Manual
OpenAI's harness engineering team found that agents perform better with a concise architectural "map" (module boundaries, naming conventions, key patterns) than with exhaustive documentation. The harness constrains the solution space so the model can navigate it, rather than overwhelming it with every possible detail.
The Analogy That Stuck
The term "harness" comes from horse tack: the reins, saddle, bridle, and bit that channel a powerful animal's energy into directed work. The model is the horse, immensely powerful but directionless without guidance. The harness is everything that channels that power. The engineer is the rider who provides direction.
There's a deeper analogy that maps to computing. The model is the CPU (raw computational power), the context window is RAM (working memory), the harness is the operating system (managing resources, permissions, scheduling, error recovery), and the agent is the application (the useful thing that runs on top of it all).
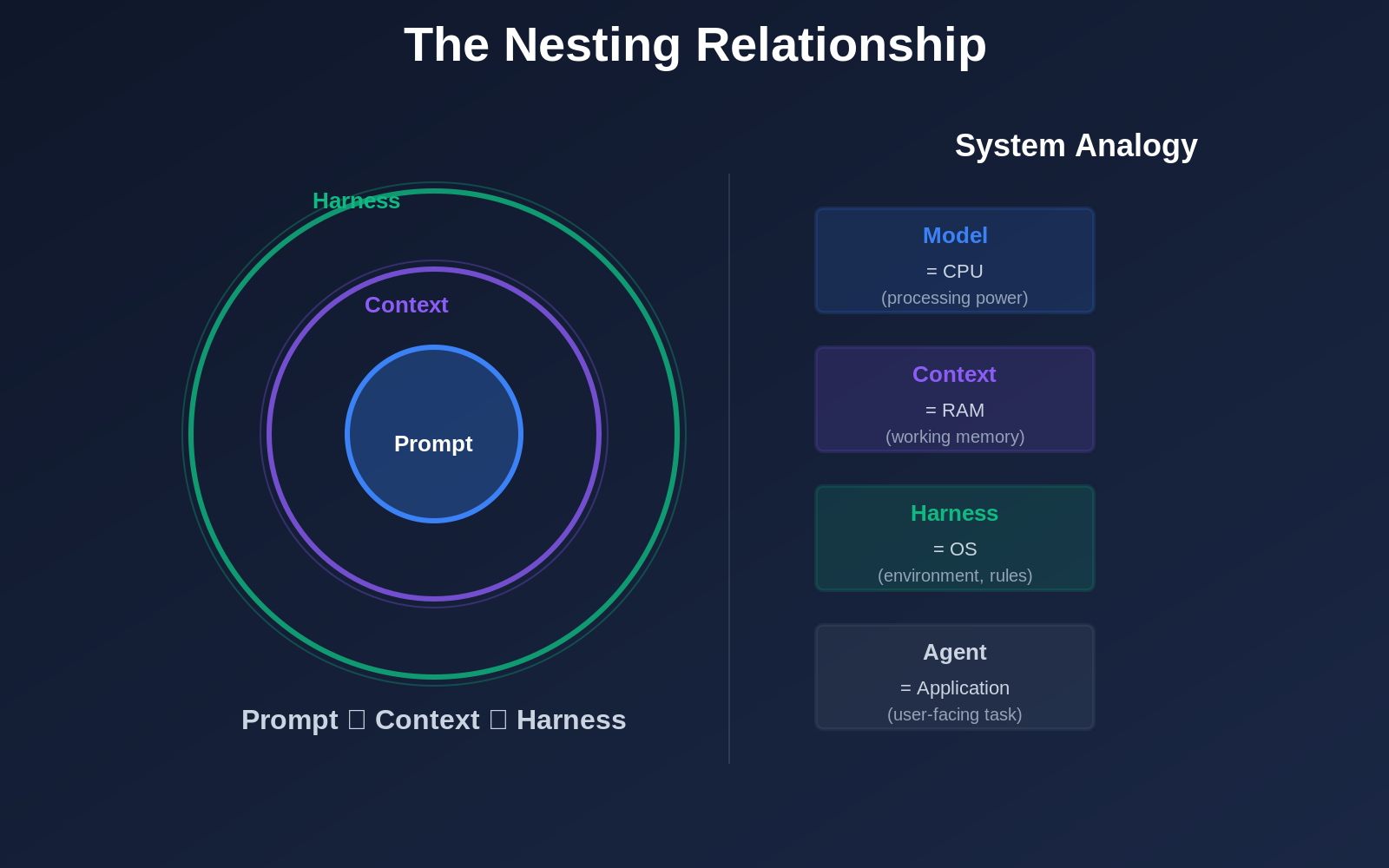
The Nesting Relationship
These three disciplines aren't competing alternatives. They're nested layers. Prompt engineering lives inside context engineering, which lives inside harness engineering:
You still need good prompts. You still need good context management. But neither is sufficient without the harness. Each layer builds on the previous one, and the outermost layer, the harness, is where the largest gains now live.
The Six Core Components of a Harness
Across the research papers, case studies, and practitioner accounts from 2025 and 2026, six components keep appearing in every effective harness design:
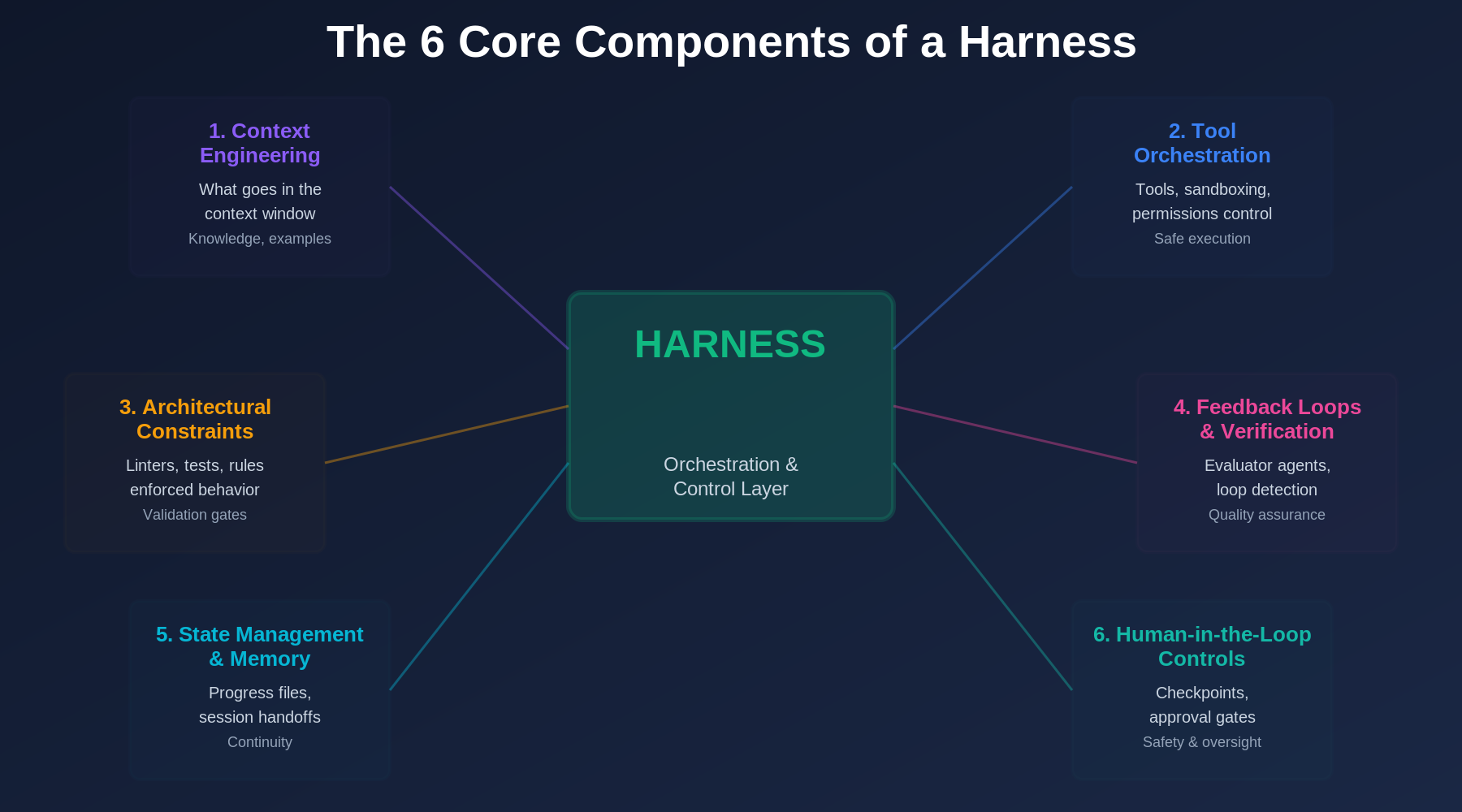
1. Context Engineering
This is where the previous era's best practices live: what goes into the context window, in what order, and with what priority. Dynamic retrieval, conversation compression, tool-result formatting. The harness manages the context window as a scarce resource, deciding what the model sees and when.
2. Tool Orchestration
What tools can the agent access? Under what permissions? With what sandboxing? Tool orchestration defines the agent's action space: which APIs it can call, which files it can read and write, what happens when a tool call fails, and how fallbacks are handled. The OpenAI Codex team, for example, ran every agent in an isolated Docker container with a fresh git checkout.
3. Architectural Constraints
These are the guardrails that prevent the model from going off the rails structurally. Linters that catch syntax errors before code is committed. Type checkers that enforce interface contracts. Dependency rules that prevent circular imports. Module boundaries that the agent isn't allowed to cross. Hashimoto encoded these as rules in his AGENTS.md: "never modify the parser without updating the test fixtures."
4. Feedback Loops and Verification
This is the component that separates a harness from a glorified prompt template. The agent's output is verified, but not by the agent itself (Anthropic's March 2026 paper found that models can't reliably evaluate their own work). Instead, separate evaluator agents, automated tests, or structural checks do the verification.
LangChain's Terminal Bench breakthrough used three middleware components that exemplify this:
# LangChain's middleware pattern for harness engineering
class PreCompletionChecklistMiddleware:
"""Before marking a task complete, verify all requirements are met."""
def process(self, agent_output):
checklist = self.extract_requirements(agent_output.task)
for requirement in checklist:
if not self.verify(requirement, agent_output):
return self.send_back_for_revision(agent_output, requirement)
return agent_output
class LoopDetectionMiddleware:
"""Detect when the agent is retrying the same failed approach."""
def process(self, agent_output):
if self.is_repeated_attempt(agent_output):
return self.force_alternative_strategy(agent_output)
return agent_output
class LocalContextMiddleware:
"""Ensure the agent has relevant local context for each step."""
def process(self, agent_output):
missing_context = self.identify_gaps(agent_output)
if missing_context:
return self.inject_context_and_retry(agent_output, missing_context)
return agent_output5. State Management and Memory
Long-running agents need persistent state. Anthropic's November 2025 paper on "Effective harnesses for long-running agents" introduced claude-progress.txt, a file the agent maintains as its own external memory, recording what it's accomplished, what it's working on, and what it still needs to do. Other state management techniques include using git history as a checkpoint system, feature requirement decomposition files, and session handoff documents that let one agent pick up where another left off.
6. Human-in-the-Loop Controls
The harness defines where humans intervene. Checkpoint-resume patterns let agents pause at critical junctures for human review. Approval gates prevent irreversible actions (deploying to production, sending emails, modifying databases) without explicit sign-off. Escalation rules define when the agent should stop trying and ask for help.
The Reliability Math
Here's the quantitative case for harness engineering. Consider a 20-step pipeline where each step succeeds 95% of the time, which is a generous assumption for many real-world agent tasks.
Without a harness, end-to-end success is:
That's a 36% success rate. For a 50-step task, it drops to 7.7%. For 100 steps, it's 0.6%. The multiplicative nature of sequential failures is devastating.
The harness fights this with verification loops (catching errors before they propagate), retry policies with alternative strategies (not just retrying the same thing), checkpoints that prevent losing progress, and evaluator agents that validate intermediate outputs. These mechanisms don't need to make each step perfect. They just need to catch and correct failures before they compound.
The Compound Failure Problem
A 95% per-step success rate sounds reliable until you chain 20 steps together and get 36% end-to-end. This is why harness engineering focuses on verification, retry, and checkpointing. Those mechanisms break the multiplicative failure chain.
The Experiments That Prove It
Four experiments from 2025 and 2026 make the case for harness engineering more convincingly than any theoretical argument.
The OpenAI Codex Experiment
Between August 2025 and January 2026, OpenAI's internal team scaled from 3 to 7 engineers, shipped 1,500+ pull requests containing over one million lines of code, and achieved roughly a 10x speed improvement over traditional development. The kicker: zero lines of code were written by humans. The engineers' entire role was harness design, which meant structuring tasks, setting up verification, defining architectural constraints, and refining the agent's operating environment based on failure patterns.
The LangChain Terminal Bench Result
LangChain's coding agent jumped from a score of 52.8 to 66.5 on Terminal Bench 2.0, moving from a Top 30 ranking to Top 5, with zero model changes. The entire improvement came from three middleware components: PreCompletionChecklistMiddleware, LoopDetectionMiddleware, and LocalContextMiddleware. The model's reasoning didn't improve. The environment around it did.
The Can.ac Hashline Experiment
This experiment changed only the edit format (how code edits were presented to the model) across 16 different LLMs. Grok Code Fast 1 went from a 6.7% success rate to 68.3%. Output tokens dropped by roughly 20%. No fine-tuning, no model changes, no prompt changes. Just a different tool format in the harness.
The Devin Context Anxiety Fix
Cognition's team noticed that their Devin agent started taking shortcuts (skipping tests, producing lower-quality code) as the context window filled up. The model was exhibiting what they called "context anxiety," rushing to finish before running out of room. The fix was pure harness engineering: they enabled a 1M token context window but capped actual usage at 200K tokens, tricking the model into thinking it had plenty of room. No model change, just environmental design.
Key Insight
In every one of these experiments, the model weights stayed identical. The competitive advantage came entirely from the harness: the constraints, tools, feedback loops, and environmental design surrounding the model.
Anthropic's Three-Agent Architecture
Anthropic's March 2026 paper, "Harness design for long-running application development," introduced what may be the most sophisticated harness architecture published to date: a three-agent system inspired by Generative Adversarial Networks (GANs).
The architecture decomposes complex tasks across three specialized agents:
The Planner breaks a high-level goal into a structured sequence of implementation tasks, each with clear acceptance criteria. It produces a plan file that serves as the project's roadmap.
The Generator executes each task in the plan, writing code, running tests, and iterating until its own checks pass. It works in isolation on one task at a time.
The Evaluator reviews the Generator's output against the Planner's acceptance criteria. Critically, Anthropic found that models cannot reliably evaluate their own work, so the Evaluator must be a separate agent instance with its own context and perspective.
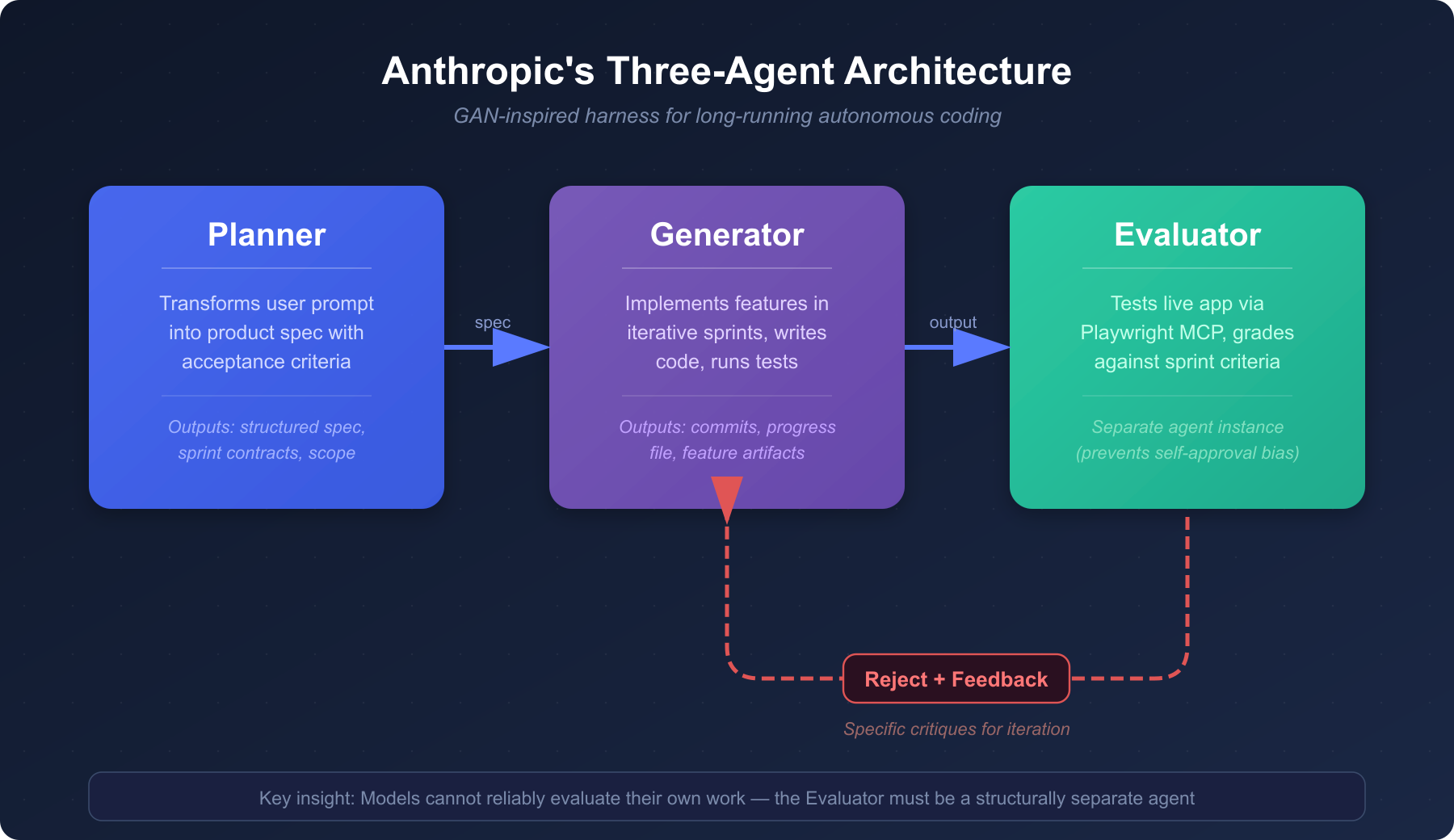
They tested this architecture by building a 2D retro game engine. The three-agent system took about 6 hours and cost roughly 200 dollars, producing a fully functional game with verified features. A solo agent given the same task finished in 20 minutes for 9 dollars, but it produced a game where the core features were broken despite the game launching successfully. The solo agent couldn't catch its own mistakes.
Martin Fowler's Framework
Martin Fowler and Birgitta Böckeler's February 2026 article on martinfowler.com introduced a useful taxonomy for classifying harness components into four categories:
Guides are the static instructions and constraints that shape agent behavior: system prompts, AGENTS.md files, architectural rules, and coding conventions. They're the equivalent of a developer onboarding doc.
Sensors are the monitoring and detection mechanisms: loop detection, progress tracking, error pattern recognition, and context window usage monitoring. They give the harness situational awareness.
Computational elements are deterministic checks and transformations: linters, type checkers, test runners, build systems, and formatters. They provide ground truth that the model's probabilistic reasoning cannot.
Inferential elements are other LLM calls used to enhance the primary agent: evaluator agents, summarizers, planners, and classifiers. They use the model's own capabilities in a structured, multi-perspective way.
The Four Levers
HumanLayer's March 2026 analysis offered a complementary framing with four customization levers for any harness: the system prompt, the tools and MCPs available, the context provided, and the sub-agents deployed. Every harness decision maps to one of these four levers.
What This Means for Practitioners
If you're a developer working with AI agents today, the Red Hat Developer article from April 2026 is a relatable starting point. The author describes their journey from "paste the Jira ticket into the AI and hope for the best" to structured harness workflows across Rust, TypeScript, and Helm charts. The transformation wasn't about switching models or learning magic prompts. It was about building systematic environments that made agents reliable.
Here's what a minimal harness looks like in practice. This is an AGENTS.md file inspired by Hashimoto's published examples:
# AGENTS.md: Project Harness Configuration
## Architecture
- This is a TypeScript monorepo using Turborepo
- Packages: `packages/core`, `packages/api`, `packages/web`
- Never import from `packages/web` into `packages/core`
## Coding Conventions
- Use `zod` for all runtime validation, never raw type assertions
- All API endpoints must have request/response schemas in `packages/core/schemas`
- Error handling: always use the `AppError` class from `packages/core/errors`
## Testing Requirements
- Every new function needs a test in the co-located `__tests__` directory
- Run `pnpm test --filter=<package>` after every change
- Integration tests must pass before marking any task complete
## Known Pitfalls
- The auth middleware caches tokens for 5 minutes. Don't test auth changes
by restarting the server, clear the cache explicitly.
- The database migration system is order-sensitive. Never modify existing
migrations, always create new ones.
- The WebSocket handler in `packages/api/ws` is NOT type-safe yet.
Validate all messages manually.
## When You're Stuck
- If a test fails more than 3 times with the same error, stop and document
the issue in `ISSUES.md` instead of continuing to retry.
- If you need to modify more than 3 files to complete a task, pause and
create a plan before proceeding.This file doesn't contain a single prompt. It's not context engineering. It's harness engineering: defining the constraints, conventions, verification requirements, and failure-handling policies that make an agent productive in a specific codebase.
The Philosophical Dimension
Andrew Maynard's February 2026 essay "What we miss when we talk about AI Harnesses" raised an important critical perspective. The horse-and-harness metaphor, Maynard argued, implies a relationship of control and subjugation, and that framing shapes how we think about what these systems should be.
It's worth sitting with the tension. On one hand, harness engineering is a pragmatic response to a real problem: powerful models need structure to be reliable. On the other hand, as these systems grow more capable and more autonomous, the metaphor of "harnessing" them may increasingly feel like the wrong frame. Are we designing operating environments for tools, or are we building cages for partners?
The answer probably depends on the task. For coding agents churning through pull requests, the harness metaphor works fine. For AI systems making consequential decisions about people's lives, we might need a richer vocabulary, one that accounts for collaboration and not just control.
Where We're Headed
Philipp Schmid offered perhaps the most forward-looking take: "The harness is the dataset. Competitive advantage is now the trajectories your harness captures." In other words, the harness doesn't just constrain the agent, it teaches it. Every failure that triggers a new rule in AGENTS.md, every retry pattern that gets encoded as middleware, every verification check that catches a class of bugs: these are training signals for the next generation of agents.
Harrison Chase argued in VentureBeat that this is what separates today's successful agents from the AutoGPT era of 2023. AutoGPT had essentially the same architecture as today's top agents: an LLM in a loop with tools. The difference isn't the architecture. It's that models are now capable enough to run reliably in a loop, and harness engineering has matured enough to catch them when they stumble.
The competitive moat in AI isn't the model anymore. It's the harness: the accumulated engineering knowledge encoded in constraints, tools, feedback loops, and verification systems. It's the operating system you build around the CPU.
The New Competitive Advantage
The model is increasingly a commodity. The harness (the constraints, tools, feedback loops, and verification systems you design around it) is where competitive advantage now lives. As Philipp Schmid put it: "The harness is the dataset."
Conclusion
The evolution from prompt engineering to context engineering to harness engineering follows a clear logic. As models grew more powerful, the bottleneck shifted from what you say to the model, to what the model sees, to the world the model operates in. Each transition happened because the previous paradigm's optimizations had asymptoted, and the next layer of the stack offered 10x or more headroom.
If you take one thing from this post, let it be this: the next time an AI agent fails at a task, don't reach for a better prompt. Don't even reach for better context. Look at the environment. Look at the constraints, the feedback loops, the verification, the recovery mechanisms. Engineer the harness, and the agent will follow.
References and Further Reading
The Origin Story Posts:
- Mitchell Hashimoto, My AI Adoption Journey (Feb 5, 2026)
- OpenAI, Harness engineering: leveraging Codex in an agent-first world (Feb 11, 2026)
- Anthropic, Effective context engineering for AI agents (Sep 29, 2025)
- Anthropic, Effective harnesses for long-running agents (Nov 26, 2025)
- Anthropic, Harness design for long-running application development (Mar 24, 2026)
Industry Analysis:
- Martin Fowler / Birgitta Böckeler, Harness engineering for coding agent users (Feb 17, 2026)
- LangChain, Improving Deep Agents with harness engineering (Feb 17, 2026)
- HumanLayer, Skill Issue: Harness Engineering for Coding Agents (Mar 12, 2026)
- Red Hat Developer, Harness engineering: Structured workflows for AI-assisted development (Apr 7, 2026)
- Harrison Chase on VentureBeat, LangChain's CEO argues better models alone won't get your AI agent to production (Mar 8, 2026)
Critical Perspectives:
- Andrew Maynard, What we miss when we talk about AI Harnesses (Feb 22, 2026)
Deep Dives:
- Andrej Karpathy, Context engineering tweet (Mid-2025)
- Karpathy's Software 3.0 talk, covered at latent.space
- Data Science Dojo, Harness Engineering: What It Is and Why It's Replacing Prompt Engineering
- Milvus, What Is Harness Engineering for AI Agents?
- SmartScope, What Is Harness Engineering: Defining the 'Outside' of Context Engineering
- LangChain Docs, Harness Capabilities